








Key to successful AIOps (Artificial Intelligence for IT Operations) is having predictive intelligence in place with a sophisticated anomaly detection system.
Whether it is your business application or the entire IT operations within your business, you want to have it all running smoothly. Without having any issues or headaches from the fall-outs when an application starts to go down. Consider Murphy’s law, ‘anything that can go wrong will go wrong’, especially systems created by human beings (we also create tools to solve that:).
We could say that applications do not work properly and are behaving in an unexpected way in such cases, or in other words it works in an anomalous way. We want to solve that immediately and even prevent it by predicting it.
Can we predict such anomalous behaviour though and how could we do that?
Predictions can be surrounded by mysteries. Looking in the future can be elusive. Therefore, I want to take you on a short journey on how anomaly prediction exactly works with predictive intelligence, what it is and how it is done, does it really work and what factors could help you in drawing up an effective strategy to make good predictions.
What is an Anomaly?
Learning how normal data of your applications behave within your business is an important aspect of anomaly detection. Normal behaviour can be evaluated against non-normal behaviour, in other words anomalous behaviour. Anomaly is an outlier that is not normal.
The learning process can be supported by supervised machine learning algorithms. The machine learning algorithms can first learn how the data behaves and whether it contains certain patterns like seasonality or trend.
Based on these insights proper statistical models can be created to detect outliers more accurately. Instead of creating random thresholds for outlier detection and characterizing it as an anomaly. As you might have noticed, I used outlier and anomaly interchangeably. However, there is a slight but important difference between an outlier and an anomaly.
The difference is mainly how the word outlier and anomaly are used and in which context. Outlier can be characterized as an issue that arises when a model is being built that makes certain assumptions about the data and indicates that the model does not describe the data well. Therefore, the model or the quality of data should be questioned whether it is the right model for the available data. The concept of an outlier is used for model building, more precisely for data points that deviate from the built model, while an anomaly is actually used to characterize unusual data outside of the data that is being used to create the model. Anomalous data can be viewed in this stage as infiltrated enemy data points that should not be in the dataset. Supervised as well as unsupervised algorithms like clustering algorithms can help to detect that.
Anomalies can be categorized in three types:
- Point anomalies
- Contextual anomalies
- Collective anomalies
When there is a single instance of data that is anomalous compared to other data points, like it is far off from the other data points, it is being characterized as an point anomaly. Although, the anomaly can be context specific.
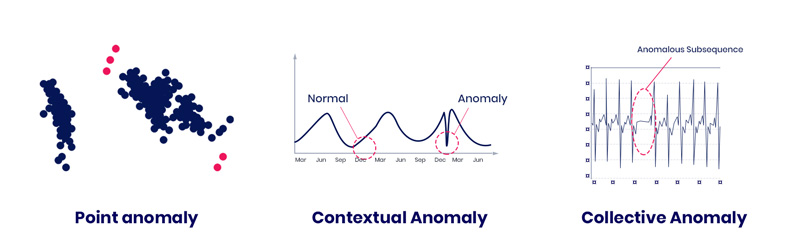
For example, CPU power might become higher when there is a lockdown, but in normal times it might be lower. The anomaly is then context specific because the jump is caused by working from home rather than that the applications are infected with harmful malware that increased CPU power. Finally, we have collective anomalies. Sometimes each outlier might not be anomalous, but a group of outliers might become an anomaly as a collective. The occurrence of a collection of outliers together would be anomalous then.
It should be mentioned here that it is an art to detect and characterize anomalies, determining which data point is a normal outlier and which data point is an anomalous outlier. Anomalies are outliers but not all outliers are anomalies. The characterization of whether an outlier is anomalous also depends on the statistical thresholds set either by an human operator or developer, or automatically set by unsupervised machine learning algorithms.
From this point onwards, we can start talking about making predictions and predict anomalies in the future with certain accuracy. Now let’s dive more into the prediction part of this.
What is a Prediction?
A prediction is a statement about a future event. Stating what could happen next or what the data would be in the next time step. That can be characterized as making predictions. Any time a prediction is made into the future, it is a forecast. All forecasts are predictions, however not all predictions are forecasts. Here is why. The process of making predictions can be deconstructed into two parts, namely in-sample predictions and out-of-sample predictions.
The sample can be a large dataset collected from several applications within your business. Sample dataset is further divided into training and test data. A classic example is that 80% of your data is assigned as a training data to train your models on, and 20% is assigned as a test data to evaluate your model’s predictive power on. In case of in-sample predictions, a model is fitted to the training data. The performance of the model is afterwards evaluated and tested against the test data. Once the performance is satisfying, then out-of-sample predictions are made. The model can make statements about what future data might look like based on the in-sample predictions from the sample dataset.
Before we dive deep into the methods of making predictions, it is important to say something about what is meant with a future event and time. A future event might be a second, a day or a certain time period away from the initial time when a prediction is made. Time is an important aspect of prediction and will be discussed later why it is important in the section about strategy.
Predictive Intelligence
You may wonder now, how are predictions then exactly made and can we really do it?
The answer is yes, it is done with amazing algorithms and yes we can, it is widely deployed by many businesses! It is characterized as predictive intelligence. First, let’s define what it means and how AI-driven statistical modelling for anomaly detection realizes predictive intelligence.
We discussed the predictive part in what a prediction is, let’s dive into the intelligence part of predictive intelligence to understand the process behind it. In this case, the example will be from the anomaly detection system within ServiceNow ITOM. Intelligence is a phenomena and can be created by collecting, structuring, analyzing and modelling data, information and knowledge. The tangible product of intelligence are insights. A decision-maker can make decisions and take action based on the insights then.
In ServiceNow ITOM, Agent Client Collector, a sort of scraper, collects operational data in time series format from the applications within the business. The data is first structured and fed into supervised machine learning algorithms, mainly a Decision Tree, Naive Bayes and a few more. It is being analyzed and based on the characteristics (features) statistical models are created.
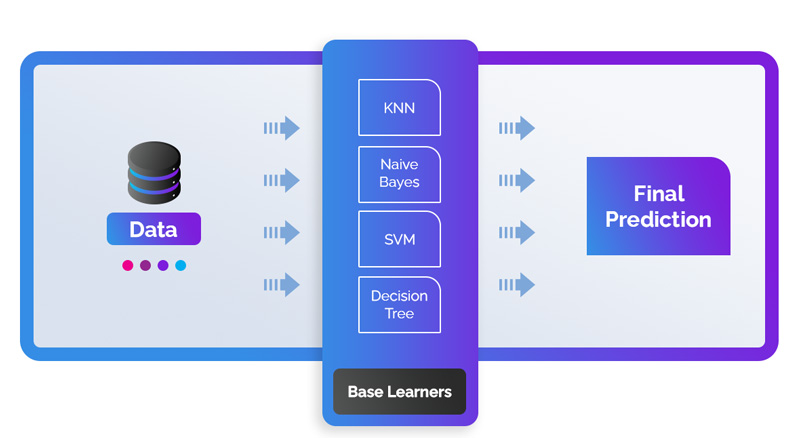
The data is being fit to the statistical model and outliers characterized as being normal outliers or an anomalous outlier. There is an anomaly scoring system to put the anomalous data into context to trigger an alert when it will cause an issue. Decision makers, whether automated or by human operators, can take action based on the insights created by the statistical models.
When a statistical model is created, it means that we can make predictions, more precisely, make a statement about what future values would look like. In this case, it makes a statement about the anomalies that are out-of-sample and detects anomalies in the future. It might occur that we might not detect or observe any anomalous behavior in-sample, however that does not necessarily mean that it might not occur in the future.
It is therefore important to have qualified and relevant information to capture all relevant factors for a good out-of-sample prediction. When the predictive part is combined with the intelligence process and anomaly detection system, we obtain predictive intelligence with anomaly detection.
Uncertainty
So far we discussed how we could make predictions and even predict anomalies that could cause an issue. Although, one cannot state with utmost certainty how the future might look like. There is some uncertainty involved in making predictions. It is rather a circumstance that has to be faced than a choice, like whether to take upon uncertainty or not.
So how accurate are the models then when facing uncertainty?
In academic literature and industry wide accuracy levels of the models are mainly between 80% and 95% (it can be even more than 95% or sometimes less than 80%, depending on the costs and benefits of obtaining certain accuracy levels), meaning that 80% to 95% of the predictions are accurate and within the set confidence thresholds.
The in-sample prediction errors are minimized by choosing the model that fitted well to the data with high accuracy scores. However, this does not rule out a black swan event. A very rare event with low probability, however it has an extreme impact when it occurs. There can still be an event where your application does stop working or works very slowly due to factors that you could not or have not captured in your model before.
The extreme event might not have even happened before. Therefore, it is important to know the limitations of AI-driven statistical anomaly detection. And have a strategy and rules in place for such events that were not predicted, but have high impact.
Strategy to deal with uncertainty
Whether you are in a position of decision making within your business, or have to make decisions in your daily life, we all have to deal with uncertainties when we make decisions for the future. There is no holy grail that could tell you with 100% certainty what the future might look like.
The future involves lots of mysteries and is mostly foggy. A mystery cannot be answered; it can only be framed by identifying the underlying critical factors (known and unknown) and by applying some sense of how they have interacted in the past and might interact in the future.
That being said, we can make some statements about the future as discussed before while trying to minimize the uncertainties. To anticipate future events rather than end up as a reactive agent dealing with surprises. Having a strategy in place for an effective predictive intelligence platform is therefore a must and cannot be avoided considering the current highly complex IT operations in place.
To conclude our story on ‘Mystery of Predictions in Anomaly Detection’, we derived 5 factors that should be considered for drawing up an effective strategy for predictive intelligence with anomaly detection while dealing with uncertainties.
On strategy
We love to conclude our story by making a call for action. In this case, we would like to do that by discussing 5 factors that could contribute to drawing up an effective strategy for your predictive intelligence capabilities.
1. Qualified data
It might be obvious or you might have already heard it a thousand times, but still the importance of having proper, qualified data is important. Having a strategy in place to collect and process data should be the cornerstone of your strategy.
Like does your business have enough historical data?
How can we collect data for variables that could influence my predictions, like alternative data from other applications that might be connected in an indirect way. Having all relevant data to capture the factors that could improve your predictions is key to successful prediction strategy.
2. Dynamic model construction
Have the right prediction method in place that can adapt to a changing environment and data. It can save you lots of trouble. Artificial intelligence and machine learning algorithms can be used for dynamic model construction. To support statistical modelling for accurate anomaly prediction for example by characterising your time series data well and adapt to changing data and context.
3. Performance
This might be part of model construction, however setting up an acceptable or desirable accuracy level for your models should be a considerable part of your strategy. The models have to be evaluated constantly because of the fact that the environment and the incoming data are dynamic. Based on evaluation, the models can be updated or adapted, whether it has to be done daily, weekly or monthly can be determined in your strategy.
4. Prediction window
Choosing the proper prediction time period should be another key pillar of your prediction strategy.
Like determining what the window of the predictions are, how much into the future do you want to look at and make predictions for? And how much historical data or alternative data sources do you need for that? The wider or more you look into the future, the more uncertain your predictions will become. That being said, in case of anomaly detection, the prediction window does not necessarily have to be one year into the future for example. Depending on the nature of your data and applications, a proper prediction window could be determined.
5. Timely decision making
Depending on the prediction window, the timing of making decisions based on predictions is important. Particularly, when and how a decision should be made. When your models predict that in the near future (depending on your prediction window) there is going to be an anomaly that could cause a certain problem, when would you make the decision to act upon it?
Like before the anomalous behavior would happen, at the time the anomalous behavior is happening or after for example? Furthermore, how automated should the decision be then, what kind of actions should be taken based on the predictions, and what to do in case of a black swan event (unexpected extreme event) happens? How should uncertainty and extreme events be managed?
These points should be considered and factored into your prediction strategy.
